

A new vulnerability headline drops, and the same question comes up: is this a CVE? This article covers what CVEs are and are not, how IDs get assigned by CNAs, what qualifies for a CVE, why records get disputed or rejected, where to find new entries, and how CVE relates to CVSS and differs from CWE.
What is a CVE?
A CVE (short for Common Vulnerabilities and Exposures) is a standardized identifier for a publicly disclosed cybersecurity issue, such as a software flaw in an application container that isolates the app and its dependencies, or an exposure that can create security risk. Each issue is assigned a CVE ID (often called a CVE number), for example in a vendor advisory, so security teams and security tools can refer to the same vulnerability unambiguously across products, scanners, ticketing, and patch workflows.
The CVE program is operated by MITRE Corporation. CVE IDs are assigned by authorized organizations called CVE Numbering Authorities (CNAs / CNA). A CVE ID is not a severity rating by itself. Severity is typically added by enrichment sources such as the National Vulnerability Database (NVD / nvd) using CVSS scoring and additional metadata. CVE is therefore an indexing system used by vulnerability catalogs and some “CVE database” sites, not a complete vulnerability database of every security vulnerability.
Does CVE list all known vulnerabilities and exposures?
No. The CVE List contains CVEs that have been publicly disclosed and assigned a CVE identifier by a CNA under the CVE Program. It does not include every known vulnerability or exposure, because many issues remain private, are not reported or validated for assignment, are not yet assigned a CVE identifier, or are outside the scope of what gets cataloged as CVEs, including some flaws found only in a container image that packages an application’s filesystem and runtime metadata for deployment.
Deploy hardened container images and track CVEs faster with
CleanStart Images.Where can you find the latest CVE list and new CVEs?
You can find the latest CVE list and newly published CVE entries in these primary sources. The following points are related to where to find the latest CVE list and new CVEs.
- Official CVE website (CVE.org) downloads and search: The CVE List is published on the CVE website, including bulk downloads of current CVE Records and updates, which container security teams use to map published CVEs to container images, runtimes, and registries for patching and risk tracking.
- Official CVE List repository (CVE List V5 on GitHub): A public repository that mirrors the official CVE List in CVE JSON format for consuming CVE data as files.
- CVE Services API: The official API used to publish CVE Records and access CVE data programmatically (commonly used by security tools and automation).
- U.S. National Vulnerability Database (NVD): NVD ingests CVEs after they are published to the CVE List and enriches them for vulnerability management with additional fields such as CVSS from the Common Vulnerability Scoring System.
- CERT Vulnerability Notes Database: A separate vulnerability notes database that publishes coordinated vulnerability reports and advisories with summaries and remediation details (not limited to the CVE List format).
How does the CVE system work?
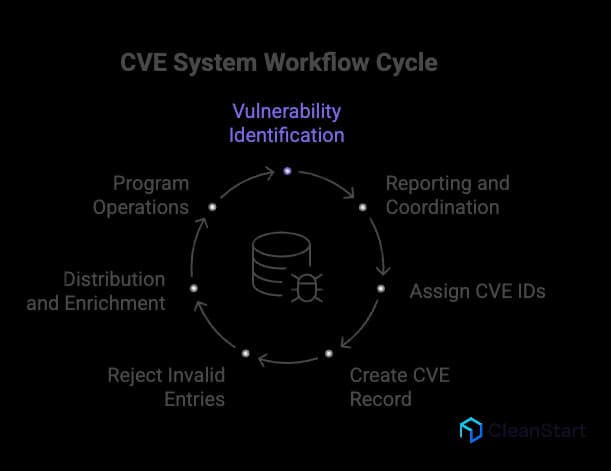
The CVE system works as a standardized workflow for turning a publicly disclosed security issue into a shared identifier and record that security teams and security tools can track across advisories, scanners, and databases.
- Vulnerability identification: A security researcher, software vendor, or open source maintainer finds a security flaw in software or firmware that negatively impacts security, such as enabling unauthorized access.
- Reporting and coordination: Details move through vulnerability reporting channels and security advisories so stakeholders can coordinate disclosure and remediation using a common reference, including how containerization packages applications into isolated runtime units that can inherit the same vulnerability across every deployed container instance.
- Assign CVE IDs through CNAs: An authorized CNA (CVE Numbering Authority) reserves or assigns a unique CVE ID for the issue. This reservation and submission workflow is handled through CVE Services, which supports CVE ID reservation and CVE record submission for publication to the CVE List.
- Create the CVE Record: The CNA publishes a CVE Record that includes the CVE ID, a brief description of the security vulnerability, and public references. CVE Records move through defined states, commonly Reserved while details are still being finalized and Published when the record is publicly available.
- Reject invalid entries when needed: If the issue is unsuitable or does not qualify, the CNA can mark it Rejected. A rejected CVE record remains visible so users know the CVE ID should not be used.
- Distribution and enrichment: Once a CVE is published, downstream systems like the U.S. National Vulnerability Database (NVD) ingest it and add enrichment used in vulnerability management and threat intelligence, including CVSS scoring from the Common Vulnerability Scoring System.
- Program operations and oversight: The CVE program is sponsored by CISA (U.S. Department of Homeland Security) and operated by The MITRE Corporation, with governance involving the CVE Board and the distributed CNA community.
What qualifies as a CVE?
A security issue qualifies to receive a CVE entry when it meets the CVE Numbering Authority criteria for inclusion in the list of publicly disclosed, publicly known information-security vulnerabilities.
- Independently fixable: The security flaw can be fixed without requiring fixes to other, separate flaws.
- Acknowledged or documented with security impact: The affected vendor acknowledges the flaw and confirms it negatively impacts security, or the reporter provides a vulnerability report that demonstrates the negative security impact and a violation of the affected system’s security policy.
- Affects one codebase: The issue maps to a single product or codebase. If the same underlying flaw affects multiple products or codebases, each affected codebase generally receives its own unique CVE listing, even when cgroups control and limit CPU and memory resources for Linux processes and containers in those different codebases.
How are CVE IDs assigned?
CVE IDs are assigned by authorized organizations under the CVE Program so the same publicly known cybersecurity vulnerability can be tracked consistently across vendors, advisories, and security tooling, including when a Dockerfile defines the base image, packages, and build steps that can introduce the vulnerable component into the resulting container image.
The following points are related to how CVE IDs are assigned.
- Assignment authority: A CVE ID is assigned by a CVE Numbering Authority within its defined scope for information security vulnerabilities affecting specific products, projects, or ecosystems.
- Scope decision: The vulnerability is matched to the correct CNA based on who owns or maintains the affected product or open source project, and whether a Root or Top-Level Root CNA delegates assignment to a subordinate CNA.
- Reservation first: The CNA reserves a unique CVE ID for the specific vulnerability, and the record can appear as RESERVED while details are being finalized.
- Publication: After validation and coordination, the CNA publishes the CVE Record with a description of the security vulnerability and references, making it available as a single CVE entry that others can read and use.
- Fallback path: If no appropriate CNA is available for the vulnerability in question, a reporter can submit a CVE request through MITRE’s CVE intake process so the issue can be routed and handled within the CVE Program.
- Program operation and sponsorship: The CVE Program is operated by The MITRE Corporation and is sponsored by the U.S. Department of Homeland Security through CISA.
- Downstream visibility: After publication, the U.S. National Vulnerability Database ingests CVE entries and may add enrichment used for prioritization and tracking.
What are common CVE assignment issues?
Common CVE assignment issues include:
- Duplicate assignments for the same vulnerability: Two parties assign CVE IDs for the same flaw, such as an insecure script used as a container entrypoint that defines the initial process executed when the container starts, and one CVE Record is later marked REJECTED as a duplicate, meaning it should no longer be used.
- CVE ID assigned incorrectly: A CVE ID is issued for the wrong issue or wrong scope and is later REJECTED as “assigned incorrectly” (the rejection reason is typically stated in the record description).
- Request withdrawn after reservation: A CVE ID is reserved and later REJECTED because the original requester withdraws it or the issue does not proceed as a CVE entry.
- Reserved CVE IDs with unpublished details: A CNA or researcher reserves a CVE ID, but the details are not yet published. These RESERVED records are not included in the U.S. National Vulnerability Database dataset, which can look like the “new CVE” is missing in tools that rely on NVD feeds.
- One flaw affecting multiple products: When a vulnerability affects more than one product, disagreements about whether it is a single CVE or multiple CVE listings can lead to duplication, later rejection, or inconsistent tracking across vulnerability databases.
- Record changes after publication: A published CVE entry can be updated, causing downstream records to change status (for example to MODIFIED in NVD), which can create mismatches between earlier advisories and the current CVE description or references.
- Downstream enrichment delays misread as “assignment issues”: The CVE List is upstream of NVD, and NVD may hold a CVE in RECEIVED or AWAITING ANALYSIS before adding enrichment (such as CPE applicability and other fields). This impacts vulnerability management workflows that use CVE IDs to track vulnerabilities affecting products through NVD-powered security tools.
What are the benefits of referring to CVEs?
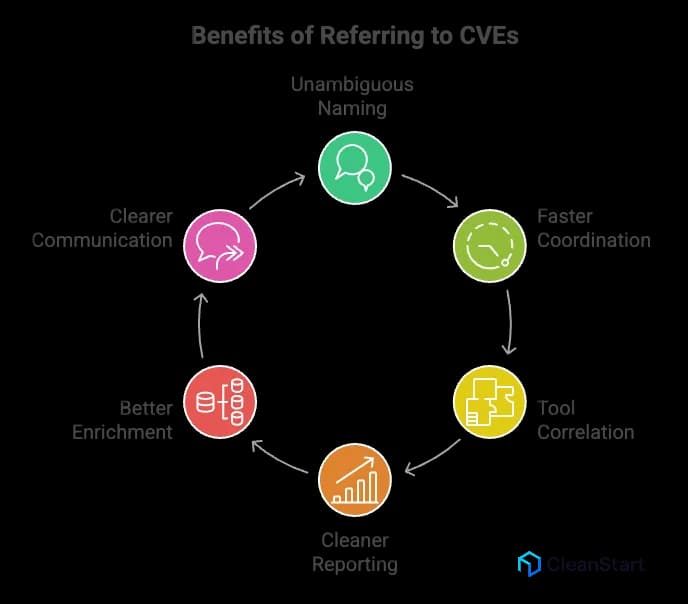
Referring to CVEs helps teams talk about the same security issue with the same identifier across systems and stakeholders.
The following points are related to the benefits of referring to CVEs.
- Unambiguous naming: A CVE provides a single common name for a specific vulnerability, reducing confusion from vendor specific labels.
- Faster coordination: Security advisories, patch notes, and incident response updates can reference the same CVE, which speeds triage and decision-making, especially when container orchestration platforms like Kubernetes schedule and manage large fleets of containers that need synchronized patching and rollout control.
- Tool correlation: Most security tools can ingest CVE references, so alerts, scans, and tickets can be linked to the same issue without manual matching.
- Cleaner reporting: Vulnerability management dashboards can de-duplicate findings and track remediation progress per CVE.
- Better enrichment: A CVE reference makes it easier to pull standardized context from sources like the U.S. National Vulnerability Database when available.
- Clearer communication: Internal teams, vendors, and auditors can align on “which exact vulnerability” is being discussed without re-explaining the flaw each time.
Standardize CVE triage and remediation across your build and deployment pipeline with
CleanStart Demo Today!What is CVSS and how does it relate to CVE?
CVSS (the Common Vulnerability Scoring System) is an open standard that assigns a numerical severity score from 0 to 10 to a security vulnerability, based on defined metrics, so organizations can compare and prioritize remediation consistently. CVSS is a severity measure, not a risk measure.
CVE and CVSS relate like this: CVE provides the unique identifier for a specific CVE vulnerability, and CVSS provides the severity score that is commonly attached to that CVE entry by enrichment sources such as the U.S. National Vulnerability Database. The CVE List feeds NVD, and NVD builds on CVE Records with added fields such as severity scores, which helps teams assess whether a container runtime like containerd or CRI-O that executes and isolates containers is exposed to a high-severity flaw.
What is the difference between CVE and CWE?
A CVE is a unique identifier for a specific, publicly disclosed security vulnerability in a particular product or component. The CVE Program is operated by MITRE Corporation.
A CWE (Common Weakness Enumeration) is a classification system for weakness types in software and hardware, such as design or coding patterns that can lead to vulnerabilities. Teams often use an SBOM that lists the software components and versions in a build to connect those components to relevant weakness categories for consistent analysis and remediation. CWE is also maintained by the MITRE-led community.
In practice, CVE answers “which exact vulnerability is this?” while CWE answers “what kind of weakness caused it?” Many CVE records are mapped to one or more CWE categories, and NVD explicitly uses CWE to classify CVEs by weakness type.
